
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- connectivity
- 서울
- platformurbanism
- 파이썬
- 웹크롤링
- 공간분석
- 도시인공지능
- spacesyntax
- pandas
- 공간데이터
- digital geography
- 베이지안뉴럴네트워크
- multinomiallogitregression
- QGIS
- 도시계획
- 도시공간분석
- 그래프이론
- 네이버
- 그래프색상
- postgres
- 서울데이터
- naver
- digitalgeography
- 베이지안
- 스마트시티
- 도시설계
- SQL
- 핫플레이스
- Python
- graphtheory
- Today
- Total
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- connectivity
- 서울
- platformurbanism
- 파이썬
- 웹크롤링
- 공간분석
- 도시인공지능
- spacesyntax
- pandas
- 공간데이터
- digital geography
- 베이지안뉴럴네트워크
- multinomiallogitregression
- QGIS
- 도시계획
- 도시공간분석
- 그래프이론
- 네이버
- 그래프색상
- postgres
- 서울데이터
- naver
- digitalgeography
- 베이지안
- 스마트시티
- 도시설계
- SQL
- 핫플레이스
- Python
- graphtheory
- Today
- Total
이언배 연구노트
[PostGRES] 주소를 활용해 소스가 다른 두 데이터의 병합 본문
소스가 다른 두 데이터를 주소 기반으로 병합해서 표기해보자.
naver_place 의 데이터는
포인트 geom, 이름, (도로명) 주소 등.
permit_place 의 데이터는
title, (도로명) 주소 + (동), (손실이 많은) 포인트 geom, 개업일 등.

우선,
1. 지난번에 고생했던 인덱싱을 개선하기 위해 두 데이터 소스에 각기 다른 id column 이름과 id 를 부여한다.
2. 주소를 기반으로 같은 건물에 있는 장소들을 분류한다.
3. 이름이 비슷한 녀석이 있으면, 인허가 데이터를 DTP로 분류한다.
일단, id 먼저 부여하자.
naver_place 의 아이디는 nid 로, permit_place 의 아이디는 pmid 로 column 을 지정하겠다.
--------------------------Set up pmid for permit_place
ALTER TABLE permit_place DROP COLUMN number;
ALTER TABLE permit_place RENAME COLUMN index TO pmid;
--------------------------Set up
ALTER TABLE naver_place DROP COLUMN id;
ALTER TABLE naver_place RENAME COLUMN index TO nid;
--------------------------permit_place 의 id 는 0부터, naver_place 의 id 는 1부터 시작하길래
--------------------------헷갈려서 1부터 시작으로 통일.
WITH numbered_rows AS (
SELECT pmid, ROW_NUMBER() OVER (ORDER BY pmid) AS rn
FROM permit_place
)
UPDATE permit_place
SET pmid = numbered_rows.rn
FROM numbered_rows
WHERE permit_place.pmid = numbered_rows.pmid;
와 진짜 거의 다왔다!!
다음으로는 주소 데이터를 비교하는 일인데,
이 주소 데이터가 오류가 상당히 많으므로, 우선 오류 먼저 잡아내도록 하자.
2-1. 시, 군, 구, 도로명, 건물본번, 건물부번으로 쪼개보자.
개념은 간단하다. 주소 column 을 띄어쓰기 기준으로 쪼개서
시도명(SD_NM), 시군구명(SIG_NM), 도로명(RD_NM), 건물본번(BD_BON), 건물부번(BD_BU)로 나누는 것.
"서울특별시 강남구 압구정로46길 5-6" 을 쪼개는 것.
naver_place에 적용했던 코드는 이것이다.
----------낭낭하게 용량을 잡아두고
ALTER TABLE naver_place ADD COLUMN SD_NM VARCHAR(40);
ALTER TABLE naver_place ADD COLUMN SIG_NM VARCHAR(40);
ALTER TABLE naver_place ADD COLUMN RD_NM VARCHAR(80);
ALTER TABLE naver_place ADD COLUMN BD_NUM VARCHAR(20);
ALTER TABLE naver_place ADD COLUMN BD_BON VARCHAR(20);
ALTER TABLE naver_place ADD COLUMN BD_BU VARCHAR(20);
----------우선 띄어쓰기 기준으로 자르되
UPDATE naver_place SET
SD_NM = split_part(RD_ADDR, ' ', 1),
SIG_NM = split_part(RD_ADDR, ' ', 2),
RD_NM = split_part(RD_ADDR, ' ', 3),
BD_NUM =
CASE ----- 지하1층, 공중2층 같은 예외들을 잡아낸다.
WHEN RD_ADDR LIKE '% 지하 %' THEN split_part(RD_ADDR, ' ', 5)
WHEN RD_ADDR LIKE '% 공중 %' THEN split_part(RD_ADDR, ' ', 5)
ELSE split_part(RD_ADDR, ' ', 4) ---건물본번과 부번이 함께 들어간다. 4-5처럼.
END;
----------그리고 건물본번과 부번을 분리하되,
UPDATE naver_place SET
BD_BON = split_part(BD_NUM, '-', 1),
BD_BU = split_part(BD_NUM, '-', 2);
----------건물 본번 부번 정보가 없어 Null 로 처리된 경우를 공백으로 바꿔주고
UPDATE naver_place SET
BD_BON = NULLIF(BD_BON, ''),
BD_BU = NULLIF(BD_BU, '');
----------사실 번호니까 INT가 맞지롱
ALTER TABLE naver_place
ALTER COLUMN BD_BON TYPE INT USING BD_BON::INT,
ALTER COLUMN BD_BU TYPE INT USING BD_BU::INT;
UPDATE naver_place SET
BD_BU =
CASE
WHEN BD_BU IS NULL THEN 0
ELSE BD_BU
END;
이걸 동일하게 permit_place에도 적용해보자.
단, permit_place 주소 정보 특징은 아래와 같다.

1. 서울'특별시'로 적혀있고
2. 띄어쓰기 기준으로 분류되어있으나
3. , 이후에는 층수가
4. () 안에는 동에 대한 정보가. 단, 학원 데이터에는 없다.
위 내용을 감안하여 코드를 짜보자.
---------------------------적절한 Column 들을 추가
ALTER TABLE permit_place ADD COLUMN SD_NM VARCHAR(40);
ALTER TABLE permit_place ADD COLUMN SIG_NM VARCHAR(40);
ALTER TABLE permit_place ADD COLUMN RD_NM VARCHAR(80);
ALTER TABLE permit_place ADD COLUMN BD_NUM VARCHAR(20);
ALTER TABLE permit_place ADD COLUMN BD_BON VARCHAR(20);
ALTER TABLE permit_place ADD COLUMN BD_BU VARCHAR(20);
ALTER TABLE permit_place ADD COLUMN UNDG INT;
--주소 끝자리에 물음표 붙인 학원들 기억하겠습니다
UPDATE permit_place SET addr = split_part(addr, '?', 1) WHERE bd_bon LIKE '%?';
--리엑팅아카데미연기뮤지컬학원 기억하겠습니다
UPDATE permit_place SET addr = '서울특별시 송파구 석촌호수로12길 43' WHERE pmid = 204832;
--미드림피부네일미용학원 기억하겠습니다
UPDATE permit_place SET addr = '서울특별시 은평구 가좌로 280' WHERE pmid = 205904;
----------우선 띄어쓰기 기준으로 자르되
UPDATE permit_place SET
SD_NM = split_part(addr, ' ', 1),
SIG_NM = split_part(addr, ' ', 2),
RD_NM = split_part(addr, ' ', 3),
BD_NUM =
CASE ----- 지하와 공중을 잡아낸다.
WHEN split_part(addr, ' ', 4) LIKE '%지하%' THEN split_part(ADDR, ' ', 5)
WHEN split_part(addr, ' ', 4) LIKE '%공중%' THEN split_part(ADDR, ' ', 5)
ELSE split_part(addr, ' ', 4) ---건물본번과 부번이 함께 들어간다. 4-5처럼.
END,
UNDG =
CASE ----- 지하를 기록한다.
WHEN ADDR LIKE '%지하%' THEN 1
ELSE 0
END,
EMD_NM = split_part(addr, '(', 2);
---------건물 번호의 쉼표를 제거하여주자. 쉼표가 있으면 INT로 안바뀌니까.
UPDATE permit_place SET
BD_NUM = split_part(BD_NUM, ',', 1);
----------그리고 건물본번과 부번을 분리하되,
UPDATE permit_place SET
BD_BON = split_part(BD_NUM, '-', 1),
BD_BU = split_part(BD_NUM, '-', 2);
----------건물 본번 부번 정보가 없어 Null 로 처리된 경우를 공백으로 바꿔주고
UPDATE permit_place SET
BD_BON = NULLIF(BD_BON, ''),
BD_BU = NULLIF(BD_BU, '');
----------사실 번호니까 INT가 맞지롱
ALTER TABLE permit_place
ALTER COLUMN BD_BON TYPE INT USING BD_BON::INT,
ALTER COLUMN BD_BU TYPE INT USING BD_BU::INT;
UPDATE permit_place SET
BD_BU =
CASE
WHEN BD_BU IS NULL THEN 0
ELSE BD_BU
END;
생각보다 주소는 정상적으로 잘 잘린 것 같다.
2-2. 같은 주소끼리 붙여보자.

또, 아까봤던대로 미용실, 이용원 등은 매우 불친절하게 네이밍 되어있으니,
항목별로 따로 붙일 수 있도록 하자.
위 테이블은 별도로 하나 만들 것인가? 아니, 만들 필요는 없다. 나중에 결과물만 알면 된다.
그 결과물마저도, id만 알면 된다.
일단, 같은 분류의 행위가 같은 건물에 있는 경우만 따져보자.
SELECT p.cls_main, p.pmid, p.title, n.nid, n.title
FROM
(SELECT pmid, title, sig_nm, rd_nm, bd_bon, bd_bu, cls_main FROM permit_place) p
LEFT JOIN
(SELECT nid, title, sig_nm, rd_nm, bd_bon, bd_bu, cls_main FROM naver_place) n
ON
(p.cls_main = n.cls_main AND p.sig_nm = n.sig_nm AND p.rd_nm = n.rd_nm AND p.bd_bon = n.bd_bon AND p.bd_bu = n.bd_bu)
WHERE nid is not null;
하.. 짜릿하다... 진작에 이렇게 차근차근 할걸...
이제 이름 유사도 순으로 분류하자.
text similarity function 을 사용할게다.
---------------text similarity 분석을 위한 extension 추가
CREATE EXTENSION pg_trgm;
---------------LEFT JOIN 으로 인허가데이터를 다 살려보자.
SELECT p.cls_main, p.pmid, p.title, n.nid, n.title, similarity(p.title, n.title) AS text_sim,
ROW_NUMBER () OVER (PARTITION BY pmid ORDER BY similarity(p.title, n.title) DESC) AS sim_rank
-- Partition 기능은 유용하다. 같은 pmid 내에서 정렬할 수 있도록 partition 별 구분을 가능케 해준다
FROM
(SELECT pmid, title, sig_nm, rd_nm, bd_bon, bd_bu, cls_main FROM permit_place) p
LEFT JOIN
(SELECT nid, title, sig_nm, rd_nm, bd_bon, bd_bu, cls_main FROM naver_place) n
ON
(p.cls_main = n.cls_main AND p.sig_nm = n.sig_nm AND p.rd_nm = n.rd_nm AND p.bd_bon = n.bd_bon AND p.bd_bu = n.bd_bu)
WHERE nid is not null --NULL인 아이들은 일단, 같은 건물 내에 네이버 검색 결과가 없는 게다.;
경험상, similarity 가 0.2만 넘어도 거의 같은 상호라고 봐도 무방한 수준이다.
문제는, simiilarity 가 0.2 이하인데도 해당 건물에서 가장 매칭이 높게 나온 지점들.

총 36,945 (결코 작은 수가 아닌) 개가 나오는데,
아예 틀린 녀석들도 보이지만
보아하니 일부는 영어로 표기해서 0이 나오기도 하고, 일부는 단순한 텍스트 배열의 차이로 인해 점수가 낮게 나온 듯 하다.
그렇다면, 이미 다른 인허가와 매칭된 title 들을 제거한다면 어떨까?
현재: 같은 건물 내에서 인허가 기준으로 NAVER 이름의 similarity 를 매칭.
다음: 같은 건물 내에서 NAVER 기준으로 인허가 이름의 similarity 를 매칭.
-> 둘이 서로 1등이라면: 볼 것도 없이 matching, 나머지 애들끼리 또 돌리면 됨.
--> matching 된 pmid, nid 를 기록함과 동시에 나머지 애들로 다시 한 번 similarity 를 매칭시킨다.
---------------WITH 는 불필요한 테이블의 생성을 방지해준다.
WITH addr_match AS
(SELECT p.cls_main, p.pmid, p.title, n.nid, n.title, similarity(p.title, n.title) AS text_sim,
ROW_NUMBER () OVER (PARTITION BY pmid ORDER BY similarity(p.title, n.title) DESC) AS pn_sim,
ROW_NUMBER () OVER (PARTITION BY nid ORDER BY similarity(p.title, n.title) DESC) AS np_sim
-- 같은 건물 내에서 permit to naver, naver to permit, 서로 text similarity 의 순서를 정해보자.
FROM
(SELECT pmid, title, sig_nm, rd_nm, bd_bon, bd_bu, cls_main FROM permit_place) p
LEFT JOIN
(SELECT nid, title, sig_nm, rd_nm, bd_bon, bd_bu, cls_main FROM naver_place) n
ON
(p.cls_main = n.cls_main AND p.sig_nm = n.sig_nm AND p.rd_nm = n.rd_nm AND p.bd_bon = n.bd_bon AND p.bd_bu = n.bd_bu)
WHERE nid is not null) --NULL인 아이들은 일단, 같은 건물 내에 네이버 검색 결과가 없는 게다.;
SELECT * FROM addr_match
WHERE pn_sim = 1 AND np_sim = 1; -- 서로 1순위인 애들만 매칭해보자
여전히 text similarity 가 0인 녀석들 (서로가 원하지 않았지만 매칭된 녀석들) 이 보이지만,
그 외에는 아주 reasonable 한 결과를 준다.

text similarity 가 0인 경우는 매우 절망적이다...
예를들어 "헤어2J살롱" 과 "HAIR 2J SALON", ":O GYM" 과 "오짐PT", 심지어 "헤어스파"와 "스파헤어" 는
도무지 이름으로 매칭시킬 방법이 없는 것인가... 이런 녀석들이 4271개나 된다.
나중에 매칭을 다 해봐야 알겠지만, 이 녀석들은 그냥 별도로 검색하는 게 더 유리할 수도 있다.
또 문제는 단순히 text similarity 가 0보다 크다고 해결되는 것이 아니라는 점.
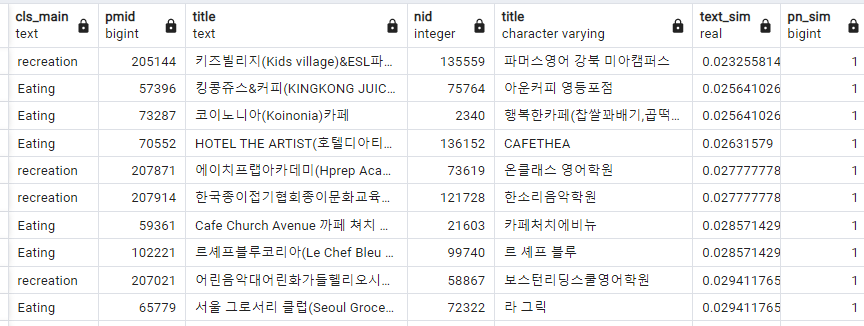
이건 또 이거 나름대로 대참사다.
text similarity 가 0.n 이상일 경우만 매칭이라고 보는 가정이 필요할 수도 있다.

이제 우리가 해야할 일은,
matching이 성공한 pmid 는 DTP로 체크하기 위해 남겨두고,
matching이 실패한 아이들끼리 다시 한 번 이름을 체크하는 것.
일단,
permit 중에서 1:1 matching 성공: 105333개
naver 중에서 1:1 matching 성공: 105341개 (?????)
permit 중에서 매칭 실패: 103321개
naver 중에서 매칭 실패: 52908개
WITH addr_match AS
(SELECT p.cls_main, p.pmid, p.title p_title, n.nid, n.title n_title,
similarity(p.title, n.title) AS text_sim,
ROW_NUMBER () OVER (PARTITION BY pmid ORDER BY similarity(p.title, n.title) DESC) AS pn_sim,
ROW_NUMBER () OVER (PARTITION BY nid ORDER BY similarity(p.title, n.title) DESC) AS np_sim
-- Partition 기능은 유용하다. 같은 pmid 내에서 정렬할 수 있도록 partition 별 구분을 가능케 해준다
FROM
(SELECT pmid, title, sig_nm, rd_nm, bd_bon, bd_bu, cls_main FROM permit_place) p
LEFT JOIN
(SELECT nid, title, sig_nm, rd_nm, bd_bon, bd_bu, cls_main FROM naver_place) n
ON
(p.cls_main = n.cls_main AND p.sig_nm = n.sig_nm AND p.rd_nm = n.rd_nm AND p.bd_bon = n.bd_bon AND p.bd_bu = n.bd_bu)
WHERE nid is not null), --NULL인 아이들은 일단, 같은 건물 내에 네이버 검색 결과가 없는 게다.;
best_matched AS
(SELECT * FROM addr_match
WHERE pn_sim = 1 AND np_sim = 1 AND text_sim > 0.15 ORDER BY text_sim, pmid),
unmatched_permit AS
(SELECT permit_place.pmid, title, sig_nm, rd_nm, bd_bon, bd_bu, cls_main, b.pmid bpmid FROM permit_place
LEFT JOIN (SELECT pmid, nid, n_title FROM best_matched) b
ON permit_place.pmid = b.pmid
WHERE b.pmid is null),
unmatched_naver AS
(SELECT naver_place.nid, title, sig_nm, rd_nm, bd_bon, bd_bu, cls_main, b.nid bnid FROM naver_place
LEFT JOIN (SELECT pmid, nid, p_title FROM best_matched) b
ON naver_place.nid = b.nid
WHERE b.nid is null)
SELECT p.cls_main, p.pmid, p.title, n.nid, n.title,
similarity(p.title, n.title) AS text_sim,
ROW_NUMBER () OVER (PARTITION BY pmid ORDER BY similarity(p.title, n.title) DESC) AS pn_sim,
ROW_NUMBER () OVER (PARTITION BY nid ORDER BY similarity(p.title, n.title) DESC) AS np_sim
-- Partition 기능은 유용하다. 같은 pmid 내에서 정렬할 수 있도록 partition 별 구분을 가능케 해준다
FROM
(SELECT pmid, title, sig_nm, rd_nm, bd_bon, bd_bu, cls_main FROM unmatched_permit) p
LEFT JOIN
(SELECT nid, title, sig_nm, rd_nm, bd_bon, bd_bu, cls_main FROM unmatched_naver) n
ON
(p.cls_main = n.cls_main AND p.sig_nm = n.sig_nm AND p.rd_nm = n.rd_nm AND p.bd_bon = n.bd_bon AND p.bd_bu = n.bd_bu)
WHERE n.nid is not null
ORDER BY p.pmid;
마지막 query 결과에서 WHERE 이하 조건문을 붙이니 query 시간이 매우 늘어나고,
1. 아예 다른 음식점 또는 미용실이 매칭되거나
2. 매칭 되더라도 한영 혼용 등 similarity 로 구분할 수 없는 경우
가 대부분이었다.
일단 건물 내에서 이름으로 붙이는 작업은 이쯤 해두고,
공간 쿼리로 넘어가보자.
'PostGRES' 카테고리의 다른 글
| [PostGRES] 웹크롤링으로 찾지 못한 인허가 데이터 붙이기 (0) | 2024.10.15 |
|---|---|
| [PostGRES] 웹크롤링 실패 인허가 데이터의 탐색 (0) | 2024.10.08 |
| [PostGRES] 공간 쿼리로 비슷한 이름 찾기 (1) | 2024.10.02 |
| [PostGRES] 도로에 인접한 건축물을 용도 별로 할당하기 (0) | 2024.04.16 |
| [PostGRES] 다른 소스의 공간 데이터 병합을 위한 text similarity 기반 전처리 (0) | 2024.04.09 |



