
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 베이지안
- 네이버
- QGIS
- 파이썬
- 그래프이론
- 웹크롤링
- 도시계획
- graphtheory
- connectivity
- multinomiallogitregression
- 도시인공지능
- 공간분석
- spacesyntax
- 핫플레이스
- pandas
- 서울데이터
- geodataframe
- 도시공간분석
- 도시설계
- digitalgeography
- 서울
- 스마트시티
- platformurbanism
- Python
- naver
- digital geography
- SQL
- 그래프색상
- 공간데이터
- postgres
- Today
- Total
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 베이지안
- 네이버
- QGIS
- 파이썬
- 그래프이론
- 웹크롤링
- 도시계획
- graphtheory
- connectivity
- multinomiallogitregression
- 도시인공지능
- 공간분석
- spacesyntax
- 핫플레이스
- pandas
- 서울데이터
- geodataframe
- 도시공간분석
- 도시설계
- digitalgeography
- 서울
- 스마트시티
- platformurbanism
- Python
- naver
- digital geography
- SQL
- 그래프색상
- 공간데이터
- postgres
- Today
- Total
이언배 연구노트
[PostGRES] DTP 데이터셋과 빌딩 데이터의 결합 본문
지난번까지 데이터셋 구축에 완료했다.
이제 빌딩 데이터셋으로 geometry 를 붙여줘야 용적률, 위치 등의 정보를 활용할 수 있으니
빌딩데이터부터 차근차근 접근해보자.
우리가 쓸 건물 데이터는 JUSO_INFO. 출처는 juso.go.kr 이다.
2021년 12월 기준이었지 아마.

PK 는 bul_num_no 와 SIG_CD 라고 하는데,
bd_mgt_sn 도 일단 모두 distinct하긴 해서 고민이 필요해보인다.
그리고 가장 열받는 포인트는 도로명이 아닌 "도로명 코드"로 되어있다는 점...
이것을 위해 DTP 에 도로명 코드를 추가해주어야 한다.
전략은
1. 도로명 코드 + 건물 본번 + 건물 부번 으로 geometry 를 매칭시키고
2. 혹시 매칭에 실패했거나, 여러개의 건물에 붙은 경우에는 point좌표로 최단 거리에 매치시키는 전략
을 활용하겠다는 거다.
우선 DTP dataset 에 도로명코드를 추가해보자.
이것을 위해서 도로명 코드 데이터베이스도 추가해주었다. (열받게)
여기에는 역시나 juso.go.kr에서 제공하는 도로명코드 데이터베이스를 활용한다.
------------무지성으로 붙였을 때 677,649개 (그런데 DTP dataset 은 200,631개)
SELECT d.*, r.rd_num rd_cd, r.sig_cd sig_cd FROM dtp_data_2024 d
LEFT JOIN road_code_total r
ON d.sig_nm = r.sig_nm AND d.rd_nm = r.rd_nm
----------이건 도대체 뭔가 하고 봤더니, 똑같은 도로명 코드가 여러개 붙은 사실을 확인했다... 도대체 왜...??
----------road_code_total 데이터에 읍면동에 따라서 도로명코드가 중복되어 기록되어있기 때문이다.
------------pmid, 도로 코드로 구분했을 떄 200,742개. 그러면 111개는 지금 중복인건데...?
SELECT distinct on (pmid, r.rd_num) d.*, r.rd_num rd_cd, r.sig_cd sig_cd FROM dtp_data_2024 d
LEFT JOIN road_code_total r
ON d.sig_nm = r.sig_nm AND d.rd_nm = r.rd_nm
------------pmid 만으로 distinct 하면 당연히 200,631개다. 111개는 도로코드가 여러개 붙었다는 얘기...
SELECT distinct on (pmid) d.*, r.rd_num rd_cd, r.sig_cd sig_cd FROM dtp_data_2024 d
LEFT JOIN road_code_total r
ON d.sig_nm = r.sig_nm AND d.rd_nm = r.rd_nm
------------이 얘기는 pmid에 도로 코드가 여러개 붙은 녀석이 있다는 얘기... 도대체 또 왜...
------------pmid, 도로 코드, 시군구 명으로 구분해도 200,742개. 111개 누군데 대체?
SELECT distinct on (pmid, rd_num, sig_cd) d.*, r.rd_num rd_cd, r.sig_cd sig_cd FROM dtp_data_2024 d
LEFT JOIN road_code_total r
ON d.sig_nm = r.sig_nm AND d.rd_nm = r.rd_nm
------------이건 같은 도로명에 코드가 복수개 있다는 얘기다...미춰버려범인 색출을 위해 부가적인 코드를 짜본다
SELECT pp.pmid, pp.rd_nm, pp.sig_nm, count(pp.rd_num) rd_count, count(pp.sig_cd) sig_count FROM
( SELECT distinct on (pmid, rd_num) d.*, rd_num, sig_cd FROM dtp_data_2024 d
LEFT JOIN road_code_total r
ON d.sig_nm = r.sig_nm AND d.rd_nm = r.rd_nm) pp --시군구명과 도로명으로 JOIN을 해보고
GROUP BY pp.pmid, pp.rd_nm, pp.sig_nm --pmid 기준으로 group한 다음에, 각각 몇개가 중복되었는지 카운트해본다
ORDER BY rd_count DESC
딱 111개의 도로에서 중복이 발생했다. 그리고 주로 범인은 충무로와 한천로58길이었다...

와아아아 미친 대전 중구에도 충무로가 있다;;;;;;; 이건 서울특별시로 제한하는 Where문으로 해결해야겠다

그럼 도대체 왜 동대문구의 한천로58길은 코드가 2개인 것인가...
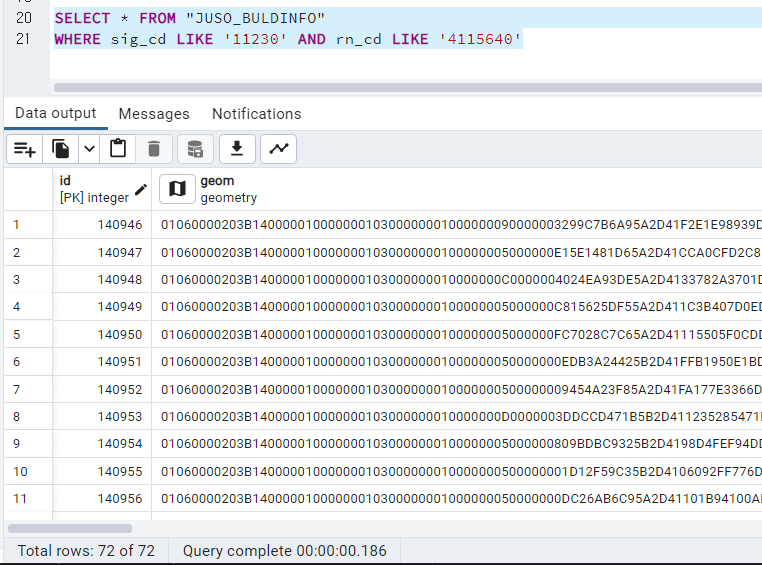
4115640으로 골랐을 때에는 빌딩 geometry 가 72개, 4121702로 골랐을 때에는 빌딩 geometry 가 1개 뿐. 그런고로, 우리는 4115640을 고르는 게 빌딩을 조인하는 데에 더 적합하다는 사실을 알 수 있다. 그러므로, 최종 query 문은
SELECT distinct on (pmid, rd_num, sig_cd) d.*, r.rd_num rd_cd, r.sig_cd sig_cd FROM dtp_data_2024 d
LEFT JOIN (SELECT * FROM road_code_total WHERE sd_nm LIKE '서울특별시' AND rd_num NOT LIKE '4121702') r
ON d.sig_nm = r.sig_nm AND d.rd_nm = r.rd_nm아아아주 지저분하지만, 이정도 전처리는 SQL세상에서 흔하디 흔하다지.
ALTER TABLE dtp_data_2024 ADD COLUMN rn_cd VARCHAR(7);
ALTER TABLE dtp_data_2024 ADD COLUMN sig_cd VARCHAR(5);
UPDATE dtp_data_2024
SET rn_cd = r.rd_num
FROM (SELECT * FROM road_code_total WHERE sd_nm LIKE '서울특별시' AND rd_num NOT LIKE '4121702') r
WHERE dtp_data_2024.sig_nm = r.sig_nm AND dtp_data_2024.rd_nm = r.rd_nm;
UPDATE dtp_data_2024
SET sig_cd = r.sig_cd
FROM (SELECT * FROM road_code_total WHERE sd_nm LIKE '서울특별시' AND rd_num NOT LIKE '4121702') r
WHERE dtp_data_2024.sig_nm = r.sig_nm AND dtp_data_2024.rd_nm = r.rd_nm;Table 의 Alter 이후 Update 는 진짜 엄청나게 신중해야 한다.
잘못 붙이면 원본 데이터 테이블도 날아가버리는 경우가 있기 때문에.
엄청나게 신중했던 결과,
데이터는 성공적으로 잘 붙었고,
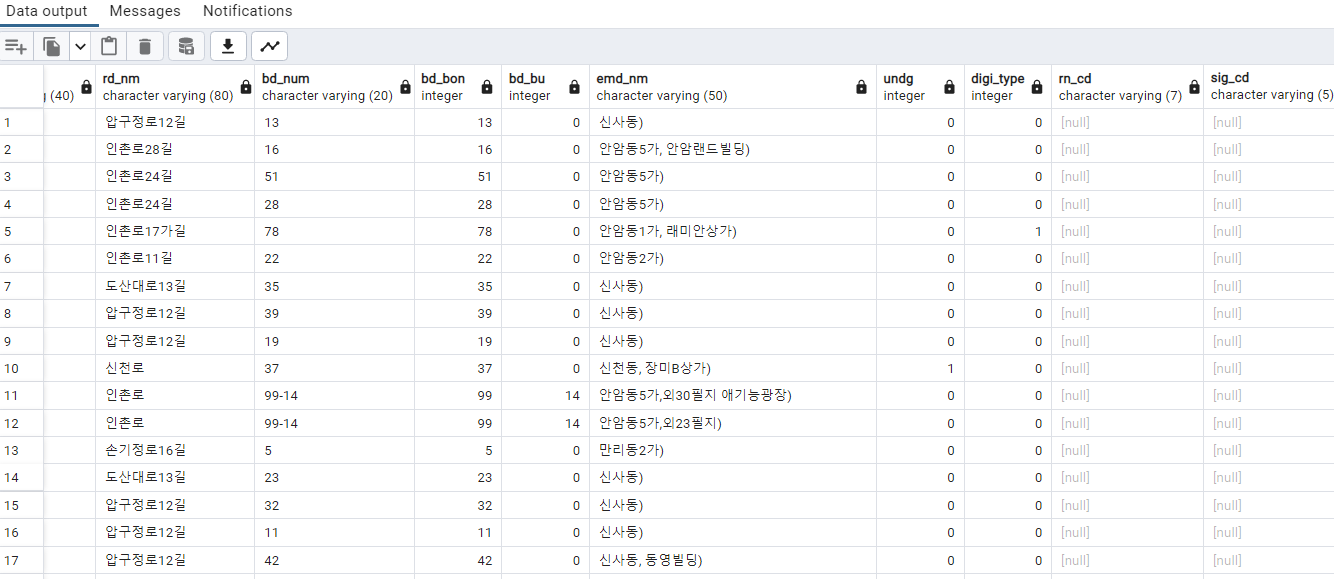
rn_cd 가 NULL인 데이터 98개를 찾았다.
찾아본 결과 도로명코드가 아예 없는 경우가 86개, 도로 자체가 입력이 잘못된 경우 (주로 학원 데이터)가 12개였다.
일단 최대한 좌표로 찾아보겠지만, 추후에는 이 데이터들을 날려도 분석 결과에 크게 문제는 없지 않을까 싶다.
이제 진짜로 building 정보를 join 해보자.
필요한 building 정보는
-geometry (geom), 층수(gro_flo_co), 지하층수(und_flo_co), 총 면적(ST_area(geom)), 건축물 용도(bdtyp_cd), 준공시기(고시일자, NTFC_DE) 등이다.
----------------------아래의 쿼리 결과는 총 471,941개, dtp 데이터셋 갯수는 200,632개...
SELECT d.*, b.sig_cd, b.rn_cd, b.bul_man_no, b.gro_flo_co, b.und_flo_co, ST_area(b.geom) total_area, b.bdtyp_cd, b.ntfc_de
FROM dtp_data_2024 d
LEFT JOIN "JUSO_BULDINFO" b
ON d.sig_cd = b.sig_cd AND d.rn_cd = b.rn_cd AND
d.bd_bon = b.buld_mnnm AND d.bd_bu = b.buld_slno
---------------------일단 중복을 제거해야 하는 게 제법 된다는 얘기고...
---------------------NULL 뜬 게 1648개다...
SELECT d.*, b.sig_cd, b.rn_cd, b.bul_man_no, b.gro_flo_co, b.und_flo_co, ST_area(b.geom) total_area, b.bdtyp_cd, b.ntfc_de
FROM dtp_data_2024 d
LEFT JOIN "JUSO_BULDINFO" b
ON d.sig_cd = b.sig_cd AND d.rn_cd = b.rn_cd AND
d.bd_bon = b.buld_mnnm AND d.bd_bu = b.buld_slno
WHERE b.sig_cd IS NULL and b.bul_man_no IS NULL
NULL이 뜨는 이유. 뭐 별다른 게 있나. 그냥 빌딩 geometry 에서 누락되었을 수도.
저 녀석들도 geometry 기반 쿼리에 참가를 시켜야 할 거고...
그러니까 고로, dtp_data_2024 가 200,631개
그 중에서 1:1로 이쁘게 건물로 얌전히 들어간 애들이 173,014개
하나에 여러개건, 하나에 하나도 못붙었건 뭔가 건물 지번으로만은 해결이 안되는 녀석들이 27,617개.
1:1 매칭에 실패해서 좌표를 뽑건, geometry 로 join을 하건, 후처리를 해줘야 하는 녀석들을 뽑아보자.
----------------------------------이 쿼리 결과, 총 27,617 개의 1:다 OR 1:0 매칭 DTP들이 나왔다.
SELECT pmid, count(buld_id) FROM
(SELECT d.*, b.bul_man_no||'_'||b.sig_cd buld_id, b.bul_man_no, b.gro_flo_co, b.und_flo_co, ST_area(b.geom) total_area, b.bdtyp_cd, b.ntfc_de
FROM dtp_data_2024 d
LEFT JOIN "JUSO_BULDINFO" b
ON d.sig_cd = b.sig_cd AND d.rn_cd = b.rn_cd AND
d.bd_bon = b.buld_mnnm AND d.bd_bu = b.buld_slno) dtp_buld --PK를 buld_id로 하나 만들어주고
GROUP BY pmid
HAVING count(buld_id) != 1 --pmid하나당 buld_id하나를 붙이지 못한 애들을 뽑아준다
이 녀석들을 안전하게 x,y 좌표로 공간 쿼리를 날려도 되는 걸까...?
1. x가 null 이거나 x가 0이어서 공간쿼리가 안되는 녀석들이 1000여개 있다.
2. 인허가 데이터의 x,y좌표를 못믿겠다.
QGIS에서 직접 찍어보자.
CREATE TABLE one_to_notone AS
(WITH
one_to_nothing AS
(SELECT pmid, count(buld_id) FROM
(SELECT d.*, b.bul_man_no||'_'||b.sig_cd buld_id, b.bul_man_no, b.gro_flo_co, b.und_flo_co, ST_area(b.geom) total_area, b.bdtyp_cd, b.ntfc_de
FROM dtp_data_2024 d
LEFT JOIN buld_info b
ON d.sig_cd = b.sig_cd AND d.rn_cd = b.rn_cd AND
d.bd_bon = b.buld_mnnm AND d.bd_bu = b.buld_slno) dtp_buld
GROUP BY pmid
HAVING count(buld_id) != 1)
SELECT d.*, ST_Transform(ST_SetSRID(ST_MakePoint(x, y), 5174), 5179) geom FROM dtp_data_2024 d
LEFT JOIN one_to_nothing
ON d.pmid = one_to_nothing.pmid
WHERE one_to_nothing.count IS NOT NULL)
One to many 인 케이스들이 여러개.
일단

집합 건축물(아파트 단지, 캠퍼스, 멀티플렉스 등) 에 포함되어있어서 어느 건축물인지 구분이 안갈 때. (아니 그럼 얘들은 buld_man_no로 구분되는 건가)

건축물 자체가 2~3개여서 구분이 안갈 때.
얘들을 가장 가까운 곳으로 퉁쳐서 잡는 게 맞는 건가...
맞지. 이게 최대한이지 뭘 더 어떻게 할거야?
사실 NAVER에 검색해보는 방법이 있다.
########################################Module Import
import psycopg2 as psql
import pandas as pd
from sqlalchemy import create_engine
import os
import sys
import urllib.request
import json
######################################## Python + PSQL Setting
conn = psql.connect(host = '우헿', port = 5432, user = '우헿헿', password = '우헤헤헿', database = '우히호')
engine = create_engine('postgresql+psycopg2://우헿헿:우헤헤헿@우헿:5432/우히호')
df = pd.read_sql('SELECT pmid, title, addr, rd_nm, digi_type FROM one_to_many', con = conn)
######################################## Crawling 을 위한 세팅
client_id = "네하하하"
client_secret = "네호호호" #NAVER API 키를 불러오고
######################################## 5000개마다 저장해줄 거다.
i = 0
columns = ['pmid', 'p_title', 'p_addr', 'n_title', 'n_addr', 'n_category', 'n_x', 'n_y']
df5000 = pd.DataFrame(columns = columns)
for s in range(i*5000, (i+1)*5000):
title = df.loc[s]['title']
rd_nm = df.loc[s]['rd_nm']
try:
encText = urllib.parse.quote(rd_nm + ' ' + title) # 도로명 + 이름이 가장 정확하게 나오는 것 같다
except: pass
url = "https://openapi.naver.com/v1/search/local.json?query=" + encText # JSON 결과
request = urllib.request.Request(url)
request.add_header("X-Naver-Client-Id",client_id)
request.add_header("X-Naver-Client-Secret",client_secret)
response = urllib.request.urlopen(request)
rescode = response.getcode()
if(rescode==200):
response_body = response.read()
js = json.loads(response_body.decode('utf-8'))
js_total = len(js['items'])
new_rows = []
if js_total > 0:
for q in range(js_total):
new_row = {'pmid': df.loc[s]['pmid'],
'p_title': df.loc[s]['title'],
'p_addr': df.loc[s]['addr'],
'n_title': js['items'][q]['title'],
'n_addr': js['items'][q]['roadAddress'],
'n_category': js['items'][q]['category'],
'n_x': js['items'][q]['mapx'],
'n_y': js['items'][q]['mapy']} #이번 크롤링에서 우리 목표는 이 n_x, n_y를 얻는 것이고
new_rows.append(new_row)
df5000 = pd.concat([df5000, pd.DataFrame(new_rows)], ignore_index = True)
else:
print("Error Code:" + rescode)
df5000.to_csv(f'one_to_many_crawl_1/api_crawl_step1_{(i+1)*5000}.csv')
##########################################크롤링 결과가 기존 공간이랑 아예 쌩뚱맞게 나오는 경우가 있는데, 그건 후처리로 보정해줄 필요가 있다
크롤링 결과는 위와 같다.
결과물이 안나온 녀석들은 NDTP(이길 바라고),
걸러내야 할 녀석들은 주소가 안맞지만 네이버가 막무가내로 return한 녀석들이다.
Python으로 모두 불러와서 걸러내보자.
그럼 이 27,617개들을 크롤링 돌려서 나온 검색 결과는 총 10,976개
걔들 중에서 실제로 크롤링이 잘 된 애들을 골라내보자.
df_concat[df_concat['n_addr'].apply(lambda x: isinstance(x, float))]
네이버 상으로 주소가 안적혀있는 괴짜들이 있긴 하다만, (그 와중에 푸드트럭까지 결과가 나오다니 세상에마상에)

크롤링 결과는 총 10,793개의 쿼리 결과를 주고, (one_to_many가 25,969개였던 걸 생각하면... 네이버 좌표로 매칭은 10000개 정도만 가능하다는 뜻)
그 중 9,726 개는 같은 주소 (인허가 데이터 상의 결과물을 네이버 좌표로 표현할 수 있음)

1067개는 다른 주소다. 보아하니 인천에서 나온 쌩뚱맞은 녀석들도 있지만, 대부분은 건물 번호가 한두개 정도만 다른,
그러니까 아마도 이사를 했거나 인허가 상 주소를 잘못 기입했을 것으로 보이는 녀석들이 있다.
이 경우에는 당연히 네이버의 좌표를 따르는 게 맞지.
그리하여 내 생각에는,
"구 명 + 도로명 + 건물 번호 첫째 자리" 까지 같은 애들은 같은 녀석으로 보는 게 맞다는 주장이다.
그럼 네이버 좌표를 얻을 수 있는 데이터들을 골라내보자.
import pandas as pd
from sqlalchemy import create_engine
from glob import glob
filenames = glob('./one_to_notone_cralw_result/*.csv') #one_to_many, one_to_nothing 의 크롤링 결과를 모아놨다.
dfs = []
for file in filenames:
t = pd.read_csv(file, index_col = 0)
dfs.append(t)
df_concat = pd.concat(dfs)
df_concat = df_concat[~df_concat['n_addr'].apply(lambda x: isinstance(x, float))] #네이버 상의 주소가 찐빠인 경우 제외
def split_ro(x):
try: #제대로 주소가 기입이 안되어있는 몹쓸 녀석들이 있어서 일부 제외해준다.
x = x.split(',')[0] #쉼표 앞에만 본다
return x.split(' ')[1] + ' ' + x.split(' ')[2] + ' ' + x.split(' ')[3][:1] #구, 도로명, 건물주소
except: return x
df_matched = df_concat[df_concat['p_addr'].apply(split_ro) == df_concat['n_addr'].apply(split_ro)]
# 굉장히 충격적인 사실. naver api 에서 나오는 좌표는 .을 뺀 4326 좌표계다... 소수점을 추가하기 위해 나눗셈을 가미하자
df_matched['n_x'] = df_matched['n_x']/10000000
df_matched['n_y'] = df_matched['n_y']/10000000
engine = create_engine('postgresql+psycopg2://이야:야하@우호:5432/이히')
df_matched.to_sql('naver_coordinates', con = engine, chunksize = 1000)
##############코드를 돌린 결과, 네이버 좌표를 쓸 수 있는 10,182개의 데이터를 얻었다.
10,182개의 pmid 는 네이버 상의 x, y 좌표를 붙여서 geometry 를 추가해주자.
ALTER TABLE naver_coordinates ADD COLUMN geom GEOMETRY;
UPDATE naver_coordinates
SET geom = ST_Transform(ST_SetSRID(ST_MakePoint(n_x, n_y), 4326), 5179);
이렇듯, 아파트 단지 안에 있어서 단지의 좌표로만 나와있거나,
건물 2개 중에 하나를 찍어야 하던 상황에서
보다 정확한 좌표 정보를 제공할 수 있게 되었다는 뜻이다.
아니 근데 아무리 봐도 10000개만 나온 게 말이 안돼.
검색이 안된 애들 중에서 DTP 가 7684개란 말이야.
(심지어 one_to_many 에서 7412 개던 NDTP 가, 이번 검색을 거치고 나니 7,151개로 줄었단 말이지... 저 339개는 색출해내서 DTP로 업데이트 해야겠다...)
저 DTP들만 한번 더 검색해봐야겠어.
---------------------------------one_to_many 중에서 검색이 안된 애들, 그 중 NDTP가 아닌 애들은 8739개다
SELECT ot.* FROM one_to_many ot
LEFT JOIN naver_coordinates ng
ON ot.pmid = ng.pmid
WHERE ng.pmid IS NULL AND digi_type != 0;
와 근데 이게 왜 쿼리 결과가 안나오지...?
그리고 가장 큰 문제는, NDTP 는 결국 좌표 정보가 없으니 집합건축물의 중심에 붙여야 한다는 건데,
이러면 논문에서 주장했던 "NDTP는 집합 건축물 안에 있어서 최근접 도로까지의 거리가 멀다" 라는 주장이 나가리라는 사실이다.
검색해도 안나온다... 왜 쿼리가 안될까...
일단 여기에 막혀있을 때가 아니다. 진짜로 이제 공간 쿼리로 빌딩 붙여야 해...
우선 5개 이상의 집합건축물에 붙은 NDTP를 얻는 코드를 저장해두고
----------------------------------NDTP 중에서 집합건축물에 포함되는 애들이 총 2,721개
SELECT pmid, count(buld_id) FROM
(SELECT d.*, b.bul_man_no||'_'||b.sig_cd buld_id, b.bul_man_no, b.gro_flo_co, b.und_flo_co, ST_area(b.geom) total_area, b.bdtyp_cd, b.ntfc_de
FROM dtp_data_2024 d
LEFT JOIN buld_info b
ON d.sig_cd = b.sig_cd AND d.rn_cd = b.rn_cd AND
d.bd_bon = b.buld_mnnm AND d.bd_bu = b.buld_slno) dtp_buld
WHERE digi_type = 0
GROUP BY pmid
HAVING count(buld_id) > 5-------------------총 27,617 의 one-to-notone 들 중에서, naver로 좌표를 찾은 10,182개의 좌표를 바꿔준다.
UPDATE one_to_notone
SET geom = ng.geom
FROM naver_coordinates ng
WHERE one_to_notone.pmid = ng.pmid
자, 이제 one-to-many 에 해당하는 녀석들은 이 좌표를 가지고, 가장 가까운 건축물을 붙이는 작업을 할 거다.
그 전에!!

정신 못차리고 0,0 에 찍혀있거나 Null이 찍혀있는 325개 녀석들을 처단해준 녀석들만 geom에 붙여주자.
솔직히 쟤들은 빼자. 좌표도 없고 건물이랑도 매치 안되는 애들을 무슨 수로 붙이냐.
----------------이렇게 총 266,37개의 dtp 들에게도 빌딩 id와 geometry 를 할당해줬다.
CREATE MATERIALIZED VIEW dtp_geom_matched AS
(WITH
many_buld_match AS --pmid 마다 같은 주소를 가진 빌딩들의 key 를 left join 으로 붙여주자
(SELECT pmid, buld_id, geom, buld_geom FROM
(SELECT d.*, b.bul_man_no||'_'||b.sig_cd buld_id, b.bul_man_no, b.gro_flo_co, b.und_flo_co, ST_area(b.geom) total_area, b.bdtyp_cd, b.ntfc_de, b.geom buld_geom
FROM geom_match_dtp d
LEFT JOIN buld_info b
ON d.sig_cd = b.sig_cd AND d.rn_cd = b.rn_cd AND
d.bd_bon = b.buld_mnnm AND d.bd_bu = b.buld_slno) dtp_buld),
ranked_matches AS --pmid 에 붙은 빌딩들 중, pmid의 포인트에 가장 가까운 객체만을 남긴다.
(SELECT pmid, buld_id, geom, buld_geom, ST_Distance(geom, buld_geom) AS distance,
ROW_NUMBER() OVER (PARTITION BY pmid ORDER BY ST_Distance(geom, buld_geom)) AS rank
FROM many_buld_match)
-----------------One to many 인 애들한테 가장 가까운 빌딩들을 할당해줬다. 이 materialized view 는 25969개다.
SELECT pmid, buld_id, geom, buld_geom FROM ranked_matches
WHERE rank = 1);
거의 다 왔다...
이제 one-to-one match된 애들에다가 저 dtp_geom_matched를 합쳐주기만 하면 된다!!!
아아아아앍!!!!씨 돌아버려!!!!! 좌표는 얻었는데 빌딩 매치를 안한 one-to-nothing 들한테도 빌딩을 붙여줘야한다!!!아아아악!!!!!!!!
--------------------1036개의 bulding 이 안 붙은 dtp들에 대해서 nearest join 을 하는 결과
CREATE MATERIALIZED VIEW nearest_geom AS
(SELECT t1.pmid, t1.geom, nearest_t2.bul_man_no||'_'||nearest_t2.sig_cd buld_id, nearest_t2.geom buld_geom
FROM (SELECT * FROM dtp_geom_match WHERE buld_id IS NULL) t1 ------------안 붙은 애들만 고른다.
LEFT JOIN LATERAL (
SELECT *
FROM "JUSO_BULDINFO" t2
ORDER BY t1.geom <-> t2.geom -- KNN operator --가장 가까운 geometry
LIMIT 1
) nearest_t2 ON true);
UPDATE dtp_geom_match
SET buld_id = nearest_geom.buld_id
FROM nearest_geom
WHERE dtp_geom_match.pmid = nearest_geom.pmid;
UPDATE dtp_geom_match
SET buld_geom = nearest_geom.buld_geom
FROM nearest_geom
WHERE dtp_geom_match.pmid = nearest_geom.pmid;
CREATE TABLE dtp_data_2024_buld AS
(WITH
buld_info AS
(SELECT bul_man_no||'_'||sig_cd buld_id, bul_man_no,
gro_flo_co, und_flo_co, ST_area(geom) total_area,
bdtyp_cd, ntfc_de, sig_cd, rn_cd, buld_mnnm, buld_slno
FROM "JUSO_BULDINFO"),
one_to_one AS -----------1:1로 붙은 dtp들을 찾아낸다.
(SELECT pmid, count(buld_id) FROM
(SELECT d.*, b.buld_id
FROM dtp_data_2024 d
LEFT JOIN buld_info b
ON d.sig_cd = b.sig_cd AND d.rn_cd = b.rn_cd AND
d.bd_bon = b.buld_mnnm AND d.bd_bu = b.buld_slno) dtp_buld --PK를 buld_id로 하나 만들어주고
GROUP BY pmid
HAVING count(buld_id) = 1), --pmid하나당 buld_id하나를 붙이지 못한 애들을 뽑아준다
dtp_buld_matched AS ----------------1:1로 붙은 dtp들과 building geometry 를 붙인다.
(SELECT dtp_buld.*, b.buld_id, b.bul_man_no, b.gro_flo_co, b.und_flo_co, b.total_area,
b.bdtyp_cd, b.ntfc_de
FROM (SELECT dd.*
FROM dtp_data_2024 dd
LEFT JOIN one_to_one oto
ON dd.pmid = oto.pmid ---------1:1로 붙은 애들의 id를 이용한다.
where oto.pmid IS NOT NULL) dtp_buld
LEFT JOIN buld_info b
ON dtp_buld.sig_cd = b.sig_cd AND dtp_buld.rn_cd = b.rn_cd AND
dtp_buld.bd_bon = b.buld_mnnm AND dtp_buld.bd_bu = b.buld_slno),
dtp_geom_matched AS
(SELECT dtp_geom.*, b.buld_id, b.bul_man_no, b.gro_flo_co, b.und_flo_co, b.total_area,
b.bdtyp_cd, b.ntfc_de
FROM (SELECT ddd.* FROM dtp_data_2024 ddd LEFT JOIN dtp_geom_match dgm
ON ddd.pmid = dgm.pmid
WHERE dgm.pmid IS NOT NULL) dtp_geom
RIGHT JOIN (SELECT dgm2.pmid, buld_info.* FROM dtp_geom_match dgm2
LEFT JOIN buld_info
ON dgm2.buld_id = buld_info.buld_id) b
ON dtp_geom.pmid = b.pmid)
SELECT * FROM dtp_buld_matched --이게 173,014개
UNION
SELECT * FROM dtp_geom_matched); --이게 26,637개 (사라진 980개는 좌표가 없거나 사라진 것으로 보인다)
이리하야, 총 199,651 개의 데이터셋과 빌딩 geometry 를 붙이는데 성공~~ 했습니다~~~!!!
'PostGRES' 카테고리의 다른 글
| [PostGRES] 서로 다른 소스의 두 건물 데이터, 특히 날짜를 병합 (4) | 2024.12.09 |
|---|---|
| [PostGRES] 최단거리 기준으로 공간 변수 붙이기 (3) | 2024.12.09 |
| [PostGRES] DTP 데이터셋 완성하기 (1) | 2024.11.29 |
| ADTP 찾아내기 (1) | 2024.11.29 |
| [PostGRES] 종로의 데이터에 geometry 를 심어보자. (0) | 2024.11.08 |



