
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- 웹크롤링
- geodataframe
- 서울
- naver
- 파이썬
- multinomiallogitregression
- 도시설계
- 스마트시티
- 네이버
- 도시계획
- 인공지능
- connectivity
- digital geography
- graphtheory
- 서울데이터
- QGIS
- 공간분석
- ai철학
- Ai
- platformurbanism
- 베이지안
- VisualStudio
- 그래프색상
- 핫플레이스
- pandas
- postgres
- 그래프이론
- Python
- SQL
- 공간데이터
Archives
- Today
- Total
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
Tags
- 웹크롤링
- geodataframe
- 서울
- naver
- 파이썬
- multinomiallogitregression
- 도시설계
- 스마트시티
- 네이버
- 도시계획
- 인공지능
- connectivity
- digital geography
- graphtheory
- 서울데이터
- QGIS
- 공간분석
- ai철학
- Ai
- platformurbanism
- 베이지안
- VisualStudio
- 그래프색상
- 핫플레이스
- pandas
- postgres
- 그래프이론
- Python
- SQL
- 공간데이터
Archives
- Today
- Total
이언배 연구노트
[Python] SHAP value 의 시각화 본문
SHAP 은 날 미치게 해...
왜냐하면 솔직히 잘 모르고 쓰기 시작했거든...
진짜 모르는데 어떻게 썼지...? 문제가 심각하다

지금 문제에 봉착하게 된 건 SHAP value 결과물을 저장하고 꺼내는 과정에서 시작되었지...
한 번 돌아갈 때 940분 걸리는 코드를 세번이나 돌렸어...
빌어먹을...
문제는... 한 번 더 돌려야돼...
우선 데이터를 불러오고, 학습모델을 돌린다.
나는 Tree 모델을 썼으니, Random Forest 기준으로 작성한다.
import pandas as pd
from sklearn.linear_model import LinearRegression, LogisticRegression
import numpy as np
from scipy import stats
from sklearn.metrics import accuracy_score, confusion_matrix, precision_score, recall_score, f1_score
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier
import shap
########### 데이터 전처리
df_rf = pd.concat([df_logit, df['cls_main']], axis =1 )
X = np.array(df_rf.loc[df_rf['cls_main'] == 'club', ['roa_cls_se', 'rds_dpn_se', 'road_bt', 'dist_tord', 'dist_toapt', 'dist_tocbd', 'dist_tostation', 'gro_flo_co', 'und_flo_co', 'total_area', 'residential', 'neighborhood', 'commercial', 'work', 'factory', 'buld_age', 'lu_onlyResi', 'lu_Resi', 'lu_joonResi', 'lu_comm', 'lu_indu', 'lu_gree']].fillna(0))
Y = np.array(df_rf.loc[df_rf['cls_main'] == 'club', 'digi_type'])
X_train, X_test, y_train, y_test = train_test_split(X, Y, test_size=0.2, random_state=42)
########### 나는 Random Forest를 쓸거여
clf = RandomForestClassifier(max_depth = None, min_samples_leaf = 4, min_samples_split = 5, n_estimators = 50, random_state=42)
########### 학습시켜
clf.fit(X_train, y_train)
########### 테스트셋 한 번 먹여봐
y_pred = clf.predict(X_test)
########### 어때? 잘 나왔어?
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy:.4f}")
########### 그럼 어디 한 번 맞춰봐
cm = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:")
print(cm)
correct_predictions = cm[0,0] + cm[1,1] + cm[2,2]
total_predictions = sum(sum(row) for row in cm)
accuracy = correct_predictions / total_predictions
print("Accuracy:", accuracy)
########### 잘 맞았니?
precision_class_0 = precision_score(y_test, y_pred, average=None)[0]*100
recall_class_0 = recall_score(y_test, y_pred, average=None)[0]*100
print(precision_class_0.round(3), recall_class_0.round(3))
precision_class_1 = precision_score(y_test, y_pred, average=None)[1]*100
recall_class_1 = recall_score(y_test, y_pred, average=None)[1]*100
print(precision_class_1.round(3), recall_class_1.round(3))
precision_class_2 = precision_score(y_test, y_pred, average=None)[2]*100
recall_class_2 = recall_score(y_test, y_pred, average=None)[2]*100
print(precision_class_2.round(3), recall_class_2.round(3))
################### 최근에 ConfusionMatrixDisplay 가 독립한듯하다.
from sklearn.metrics import ConfusionMatrixDisplay
ConfusionMatrixDisplay.from_estimator(칠, X_test, y_test)
plt.title("Confusion Matrix")
plt.show()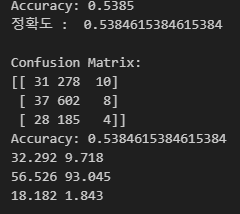
낭만없고 차가운 결과물
이제 대망의 SHAP 분석이다.
################## Explainer 객체를 만들고
explainer = shap.TreeExplainer(clf)
################## Explainer 객체에 훈련데이터를 먹여서 각 SHAP 값을 도출한다.
shap_values = explainer.shap_values(X_train)
################## 저장하고 싶을 때에는 npz 라는 파일로 저장하면 되는데,
np.savez('club_shap2.npz', shap_values)
################## 이 npz라는 파일은 "배열을 포함한 파일" 에 가깝고,
loaded = np.load('club_shap2.npz')
################## 'arr_0', 'arr_1' 등의 indexing을 자동으로 가진다. 나는 별도 indexing을 안했으니, ['arr_0']으로 풀어줘야 한다.
loaded_shap = loaded['arr_0']
################## 이렇게 해서 나온 loaded['arr_0'] 안에는 [데이터갯수 : column 갯수 : class 갯수] 의 shap 값이 저장된다..
################## 첫번째는 bar plot이다. class 별로 shap 값의 평균을 모아서 비교해준다.
shap.summary_plot([loaded_shap[:, :, 0], loaded_shap[:, :, 1], loaded_shap[:, :, 2]], X_train, plot_type = 'bar', feature_names = col_names)
################## 두번째는 beeswarm plot이다. 각 class 를 구분해서 shap 값이 어떻게 찍히는지, 결과물에 어떤 상관관계를 가지는지 보여준다.
shap.summary_plot(loaded_shap[:, :, 0], X_train, feature_names = col_names)
shap.summary_plot(loaded_shap[:, :, 1], X_train, feature_names = col_names)
shap.summary_plot(loaded_shap[:, :, 2], X_train, feature_names = col_names)
이것이 bar plot이고

이것이 beeswarm plot이다
728x90
'Python' 카테고리의 다른 글
| [Python + PostGIS] Dataframe 의 geometry 를 포함해서 PostGIS로 (1) | 2025.03.19 |
|---|---|
| [QGIS + Python] 서울사람들은 어디로 놀러다닐까 (1) | 2025.01.24 |
| [Python] Classification 모델들 (1) | 2024.12.11 |
| [Python] ANOVA F-Test, Multinomial Logit Regression (4) | 2024.12.10 |
| [Python] NAVER API로 음식점 상세 정보 검색하기 (0) | 2024.10.15 |
'Python' Related Articles
more


