
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- graphtheory
- 그래프색상
- pandas
- 공간데이터
- 핫플레이스
- 네이버
- 서울
- 도시계획
- 파이썬
- multinomiallogitregression
- postgres
- VisualStudio
- 도시설계
- naver
- 그래프이론
- 베이지안
- QGIS
- connectivity
- 웹크롤링
- 인공지능
- SQL
- 공간분석
- platformurbanism
- geodataframe
- Ai
- 스마트시티
- ai철학
- Python
- 서울데이터
- digital geography
- Today
- Total
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
- graphtheory
- 그래프색상
- pandas
- 공간데이터
- 핫플레이스
- 네이버
- 서울
- 도시계획
- 파이썬
- multinomiallogitregression
- postgres
- VisualStudio
- 도시설계
- naver
- 그래프이론
- 베이지안
- QGIS
- connectivity
- 웹크롤링
- 인공지능
- SQL
- 공간분석
- platformurbanism
- geodataframe
- Ai
- 스마트시티
- ai철학
- Python
- 서울데이터
- digital geography
- Today
- Total
이언배 연구노트
[QGIS + Python] 포인트 데이터를 사용한 hotspot 분석 본문
네이버에 등록이 안된 음식점들은 도대체 어디 몰려있는가...
네이버에 등록하지 않은 곤조있는 자영업자들은 어디 계신 건가...
이것을 위해 격자별로 NDTP, DTP, ADTP 의 갯수와 비율을 세보고, HOTSPOT 분석까지 해보자.

시작은 데이터를 늘어놓는 것 부터.
우선 서울에 250m 그리드를 만들어보자.

그리드를 만들고 싶은 만큼의 레이어를 올려놓고
"그리드 생성" 에서
"그리드 유형" 은 사각형 폴리곤으로 둔다.
"그리드 범위" 를 서울 행정동 전체로 두고,
간격은 각각 250m 씩으로 둔다. 250m인 이유는, 250m단위 이동데이터를 쓸 요량도 있고, 적당해보여서다.

이 중에서 서울에 해당하는 부분만 살리고 싶다면

"위치로 선택" 에서
그리드 레이어에서 행정동 레이어를 비교해서 선택을 하고

반대 객체를 선택한 후에 삭제해주면 깔끔하게 서울의 그리드만 남는다.

서울의 그리드 위에 Third Place가 점으로 흩뿌려져있다.
이제 갯수를 세어보자.
250m의 공간 위에 Third Place가 타입별로 몇개씩 있는지 확인할 수 있게 될거다.

방법은 2가지.
하나는 "폴리곤에 포함하는 포인트 갯수 계산" 이라는 tool을 쓸 수도 있지만,
나는 기왕 데이터도 primary key 를 철저하게 만들어놓은 김에
- "위치를 이용하여 속성을 결합" 기능에서
- intersect를 해도, contain 을 해도 되고 (point 니까 intersect면 contain이다)
- 갯수를 셀 point data의 레이어를 정한 뒤
- 갯수를 셀 field (id 면 중복 없이 싹 셀 수 있다) 를
- count 하는 방식으로 갯수를 셌다.
이 짓을 NDTP, DTP, ADTP마다 해주면 grid마다 Third Place 종류별로 갯수가 나온다.

서울에서 Third Place가 많은 갯수대로 cell 을 표현한 결과다.
나는 Third Place의 종류별 비율을 집중해서 볼 거다.
한 cell 에 Third Place 갯수별로 비율을 세보자.

F6으로 열리는 데이터테이블 창에서 필드계산기를 열고
ndtp_r = "ndtp_cnt" / "total"
dtp_r = "dtp_cnt" + "adtp_cnt" / "total" -- 이걸 더한 이유는, 플랫폼에서 검색이 되기만 하면 다 추가하기 위해. 나중에는 바꿔야 할 수도 있다.
adtp_r = "adtp_cnt" / "total" 로 수식을 넣고 계산해준다.

ndtp 의 비율이 높은 곳은 아주 중구난방으로 보인다.
이 중에서 hotspot 을 찾아내보자.

Hotspot 분석을 위해서 플러그인 중 visualist 라는 플러그인을 설치해준다.
Spatial autocorrelation 분석에 필요한 여러가지 툴을 제공해준다.

Spatial Autocorrelation 이란, 가까운 애들끼리 연관있냐? 를 확인해주는 공간 통계다.
Visualist 의 Spatial Autocorrelatoin 기능은 다음과 같다.
- Spatial Autocorrelation Map 이라는 tool 로 들어가면
- 공간 분석을 수행할 레이어와 필드를 선택하고
-LISA 분석은 2가지가 있다.
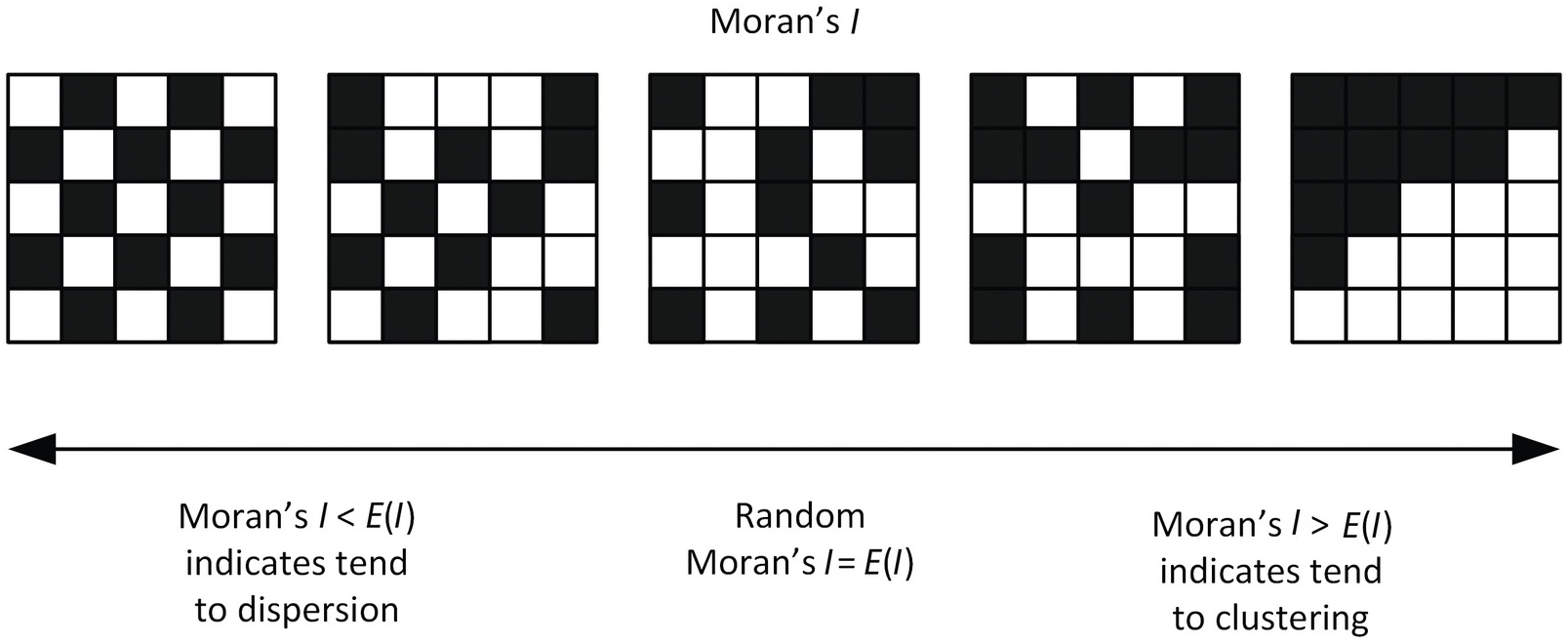
- 1. Moran's I 는 -1 ~ +1 사이로, -1이면 옆에 있는 애들끼리 아주 다름 (체스판), +1 이면 옆에 있는 애들끼리 아주 미슷함, 그 사이면은 random 함이다.

- 2. Getis' Ord 는 z-score가 낮을수록 유의미하게 coldspot (내가 낮고 옆에도 낮음), 높을수록 유의미하게 hotspot (내가 높고 옆에도 높음) 이다.
그런 의미에서 Moran's I 는 "옆에랑 비슷하냐?" 의 의미고, Getis' Ord 는 "옆이 높으면 나도 높냐?" 의 의미로, 핫스팟 분석은 Getis' Ord 를 쓰는 게 맞다.
그렇게 해서 찾은 hotspot 은

이게 NDTP의 비율이 높은 애들끼리 뭉쳐있는 hotspot 을 도출한 예시다.
significant level 0.05 이상, 그러니까 z-score가 1.96 이상인 애들만 짚으면

위랑 같이 나온다.
NDTP는 관심 없으실테니 Total Third Place로 하면,

강남, 홍대, 을지로, 여의도, 구로, 마곡, 상계, 잠실, 성수, 천호, 용산 같은 포인트들이 HOTSPOT 으로 나온다.
그러니 서울시에서 제공하는 발달상권 데이터랑 비교해도 잘 맞을 수 밖에.
'QGIS' 카테고리의 다른 글
| [QGIS + Python] 서울 생활인구 이동 데이터 탐색 (0) | 2025.01.14 |
|---|---|
| [QGIS] 도로에 가장 가까운 점들 할당하기 (0) | 2024.04.09 |

