
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- postgres
- 베이지안뉴럴네트워크
- 서울
- pandas
- 핫플레이스
- 네이버
- 웹크롤링
- connectivity
- 도시공간분석
- 파이썬
- 그래프색상
- digital geography
- 그래프이론
- 공간분석
- Python
- naver
- digitalgeography
- 서울데이터
- 도시계획
- platformurbanism
- 베이지안
- spacesyntax
- graphtheory
- 도시설계
- QGIS
- SQL
- multinomiallogitregression
- 공간데이터
- 도시인공지능
- 스마트시티
- Today
- Total
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 | 31 |
- postgres
- 베이지안뉴럴네트워크
- 서울
- pandas
- 핫플레이스
- 네이버
- 웹크롤링
- connectivity
- 도시공간분석
- 파이썬
- 그래프색상
- digital geography
- 그래프이론
- 공간분석
- Python
- naver
- digitalgeography
- 서울데이터
- 도시계획
- platformurbanism
- 베이지안
- spacesyntax
- graphtheory
- 도시설계
- QGIS
- SQL
- multinomiallogitregression
- 공간데이터
- 도시인공지능
- 스마트시티
- Today
- Total
이언배 연구노트
[Digital Geography] NAVER-ized 된 상권을 찾아보자 본문
오랜 고민과 망설임은 끝났다.
다른 논문들을 살펴본 결과, 내가 믿는 대로 밀고 나가도 충분히 가능하다는 사실을 깨달았다.
한번 가보자.

내가 build 한 과정은 이렇다.
1. Platformazation 이 진행된 상권, 그렇지 않은 상권을 나누어본다.
1-1. 여기서, platform에 등록을 했는지, 그렇지 않은지를 기준으로 그런 곳의 비율이 높은 cell 이 몰려있으면 platformazed 된 지역이라고 본다.
1-2. 굳이 platformazed 된 장소 (place) 가 아닌 지역 (area) 을 보는 이유는
1-2-1. place 단위까지 확인할 수 있는 정밀한 데이터를 취득할 수 없기 때문이고
1-2-2. 이후에 계층별 분석까지 할 건데, '특정 계층의 사람들이 많이 오는' 공간 단위를 설정하고 싶었기 때문이다.
1-3. 이 상권의 구분은 그리드 단위로 갯수를 세서, hotspot analysis 로 진행한다.
2. Platformazation 이 진행된 상권에서 발생하는 social activity 를 계측해본다.
2-1. social activity 는 경제활동, 유동인구, 방문 인구를 기준으로 분석한다.
2-1-1. 경제활동에 주목하는 이유는 내가 찾은 Third Place 에서 발생하는 social acitivity 의 간접적인 지표이기 때문이다.
2-1-2. 유동인구는 길단위 인구로 분석한다.
2-1-3. 방문인구는 동단위 여가 여행 인구 단위로 분석한다.
3. Platformazation 이 진행된 상권과 그렇지 않은 상권의 characteristics 를 분석해본다.
3-1. 각 지역이 가지는 특색과 Third Place의 종류 등을 중점적으로 분석해본다.
3-2. 각 Third Place 의 종류와 중점적인 데이터, 업종을 바탕으로 어떠한 차이점이 있는지를 비교해본다.
그럼 이제, platformazation 이 진행된 상권을 찾아보자.
일단, 각 그리드별로 갯수를 세서 Getis-Ord 로 핫스팟은 찾아뒀다.
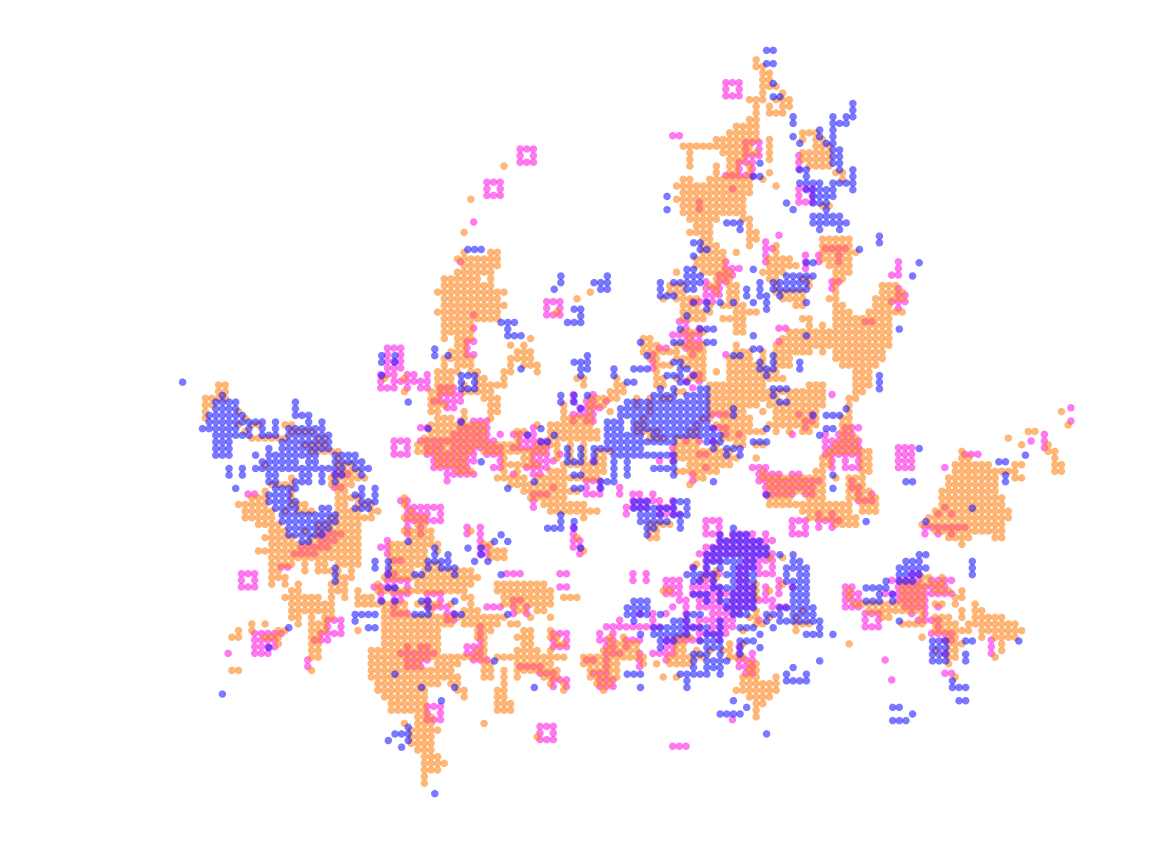
여기서 내가 결정해야 할 것.
1. 그리드로 분석할 거냐? 상권으로 분석할 거냐? 동으로 분석할 거냐?
--> 동으로 할거다. 왜냐하면 데이터가 더 잘 나와있고, 상권은 모든 spot을 다 커버하지도 못하고, commercial activity 에 대한 설명까지 덧붙이면 귀찮기 때문.
--> 그럼 동으로 하면 문제 없냐? 이걸 잘 걸러내는 작업을 해야 한다. 예를 들면,
1-1. 동 데이터로 각 hotspot을 대표하기 위해서는
1-1-1. hotspot 자체도 사람들의 방문에 주된 목적지가 되어야 하고 <예를 들어 Third Place가 몇 개 이상 있어야 한다던지>
1-1-2. Hotspot 에 해당하는 면적이 해당 동의 대부분을 차지하고 있어야 한다. 예를 들어서, 살짝 걸쳤는데 그 동에 방문하는 사람이 죄다 그 hotspot에 왔다고는 할 수 없으니까.
그럼 hotspot 자체가 사람들의 방문에 주된 목적지가 되는 곳만 걸러보자.
일단 250m 그리드로 갯수를 센 애들 중에서, 0개인 cell 을 제외하고 나머지 애들 중에서 median 을 취해보자.

하 이게 평균은 34이고 Median 은 19인데, 상당히 right skewed 되어있지 않나 싶다.
hotspot이라는 애들을 Median 보다 큰 애들로 잡으면 2853개의 cell 이고, mean으로 잡으면 1992개다.
일단 내가 뒤로 필터링할 게 꽤 있으니까 median 으로 가보자.
Hotspot 에 해당하는 면적이 동의 대부분을 차지하는 곳을 찾아보자.
Grid 단위로 hotspot 을 구하고 다른 공간 단위 (도로, 동, census 등) 로 병합하는 연구는 제법 찾아뒀다.

아니 근데 이러면 적어도 한강이랑 산지는 빼줘야 하는 거 아닌가?
그럼 <HOTSPOT 면적> / <동면적 - 녹지면적 >= 50% 면 해당 동은 hotspot에 매치되는 거로 해보자.
솔직히 무지성으로 그냥 찍어도 될 것 같긴 한데, 그래도 양적 분석할 때에는 기준이 명확해야 좋으니까.
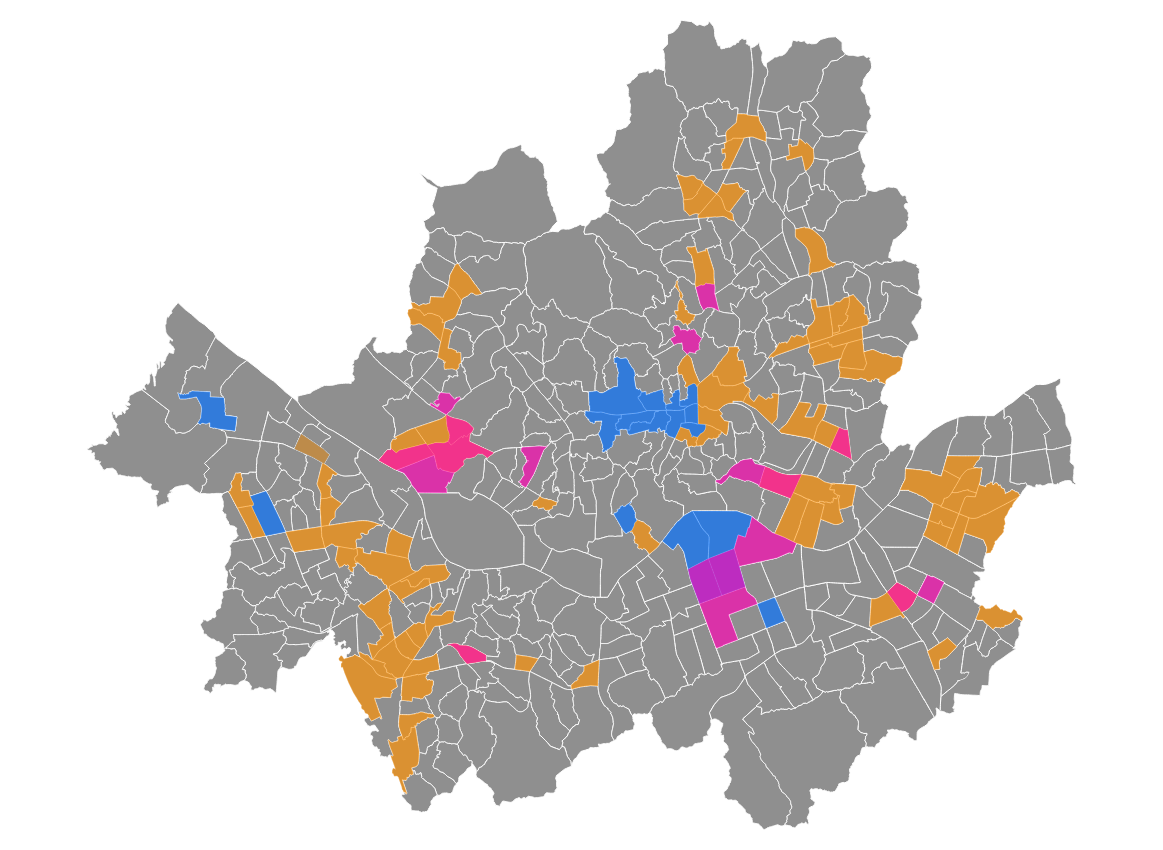
음... 뭔가... 빅데이터 분석이라기엔... 좀 부족해보이기도 하고...
저 0.5라는 기준이 그렇게 빡센가?
그래도 일단 나눠보자면,
NDTP 핫스팟은 강남(중에서도 북부), 을지로, 강서 구역이고
ADTP 핫스팟은 강남(중에서도 남부), 홍대, 성수 구역
DTP 핫스팟은 그 외 기타 등등
되시겠다.
'Digital Geography' 카테고리의 다른 글
| [Digital Geography]Geographies of Digital Exclusion (1) | 2024.10.15 |
|---|---|
| [Digital Geography] Digi-Third-Place 연구의 데이터 구득 (3) | 2024.09.27 |
| [Digital Geography] Inventing Future Cities 스터디 (0) | 2024.05.13 |
| [Digital Geography] 빅테크 기업과 디지털 시대 스터디 (0) | 2024.05.07 |
| [Digital Geography] NAVER 의 역사와 의의 스터디 (1) | 2024.05.07 |



